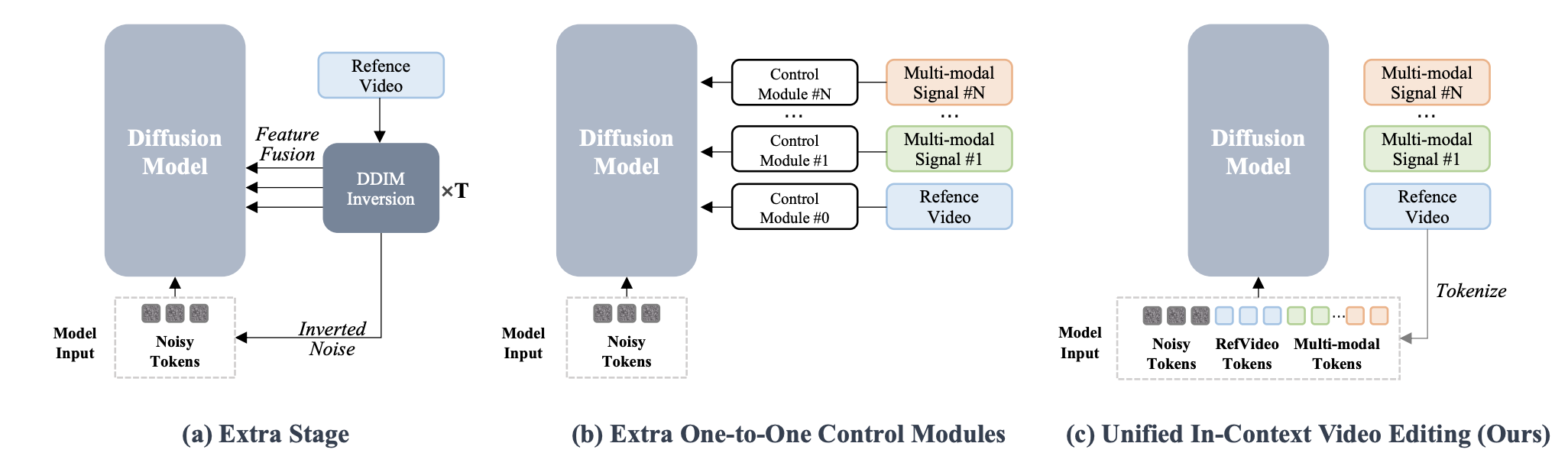
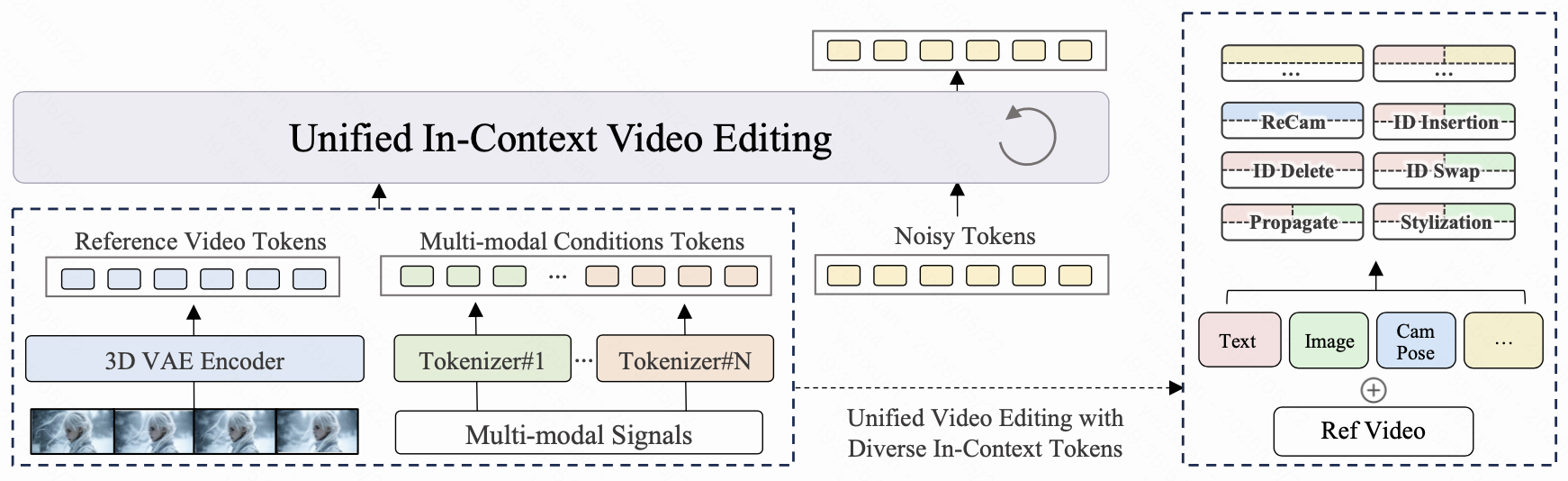
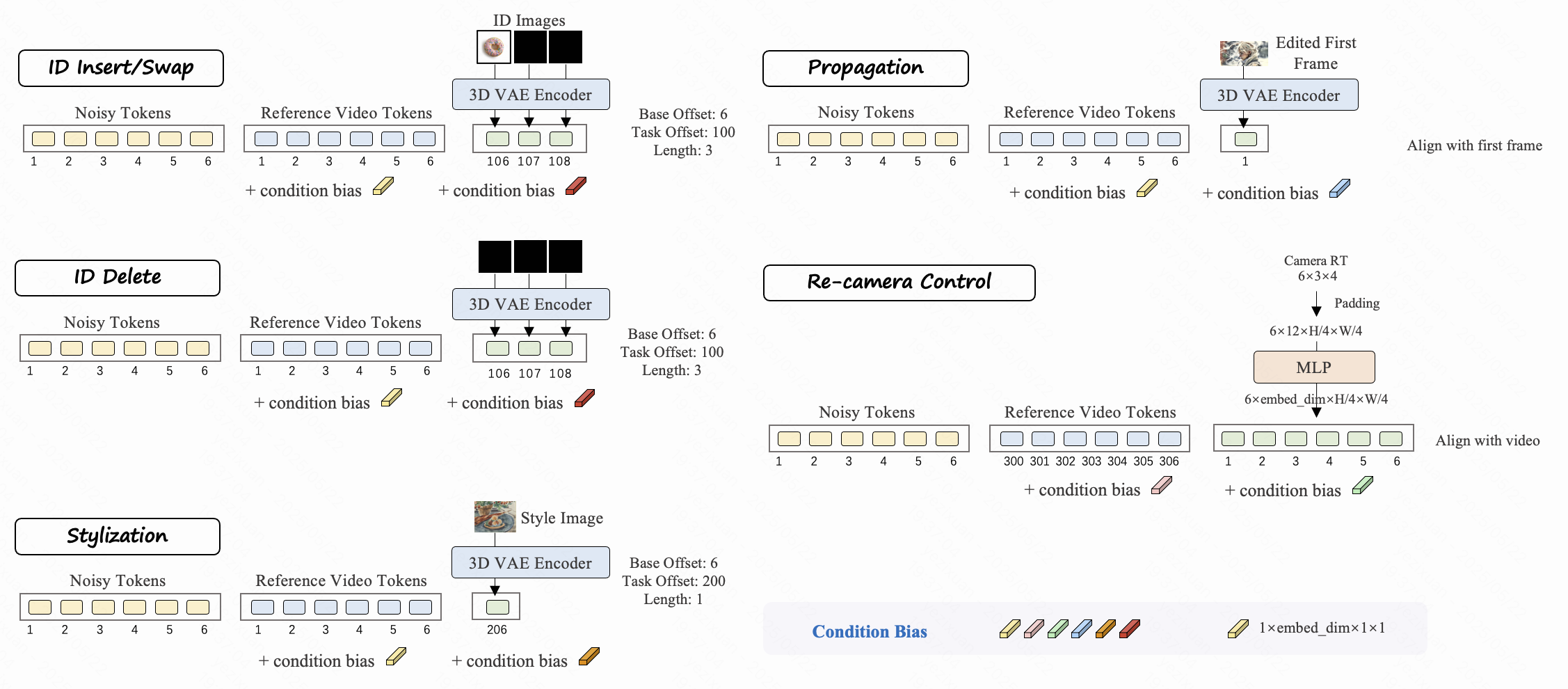
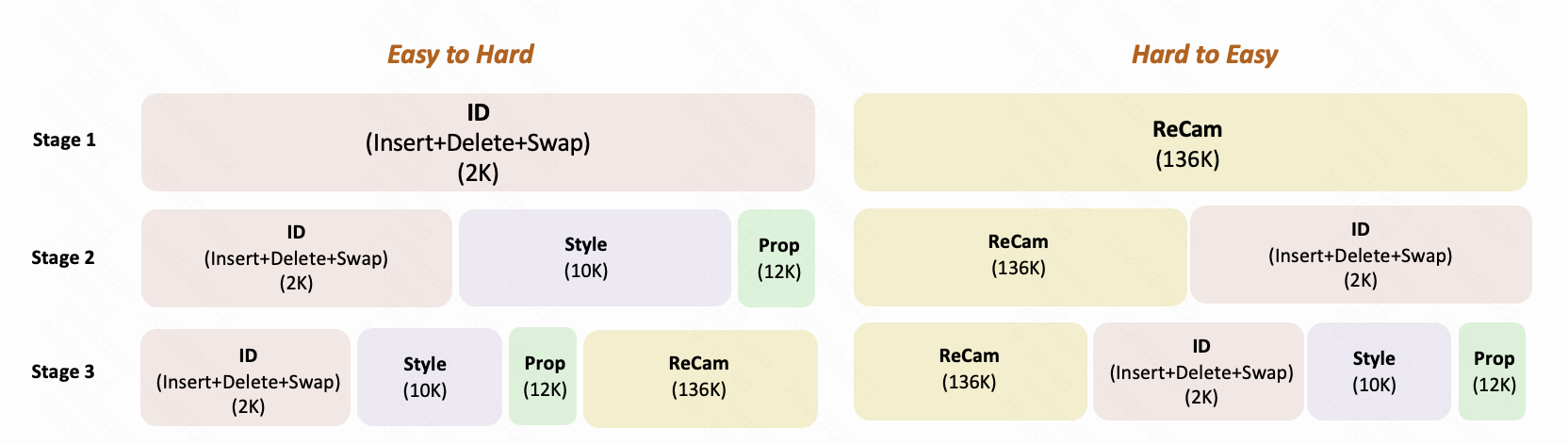
Motivation
(a) DDIM Inversion-based Methods (e.g., Video-P2P, FLATTEN)::
- Sub-optimal performance.
- Additional stage, which doubles the inference steps and overall cost.
(b) Adapter-based Methods::
- Requiring modifications to model architectures.
- Introducing parameter redundancy through the addition of adapter modules.